|
I am currently a principal researcher at Tencent Hunyuan, working on large multimodal models and physical AI foundation models. I obtained my Ph.D degree from Tsinghua University in 2023, advised by Prof. Jiwen Lu . Before that, I received B.Eng. degree from the Department of Electronic Engineering, Tsinghua University in 2018. We are hiring interns. Please feel free to drop me an email if you are interested in working with us. |

|
|
* indicates equal contribution, # indicates project lead / corresponding author |
|
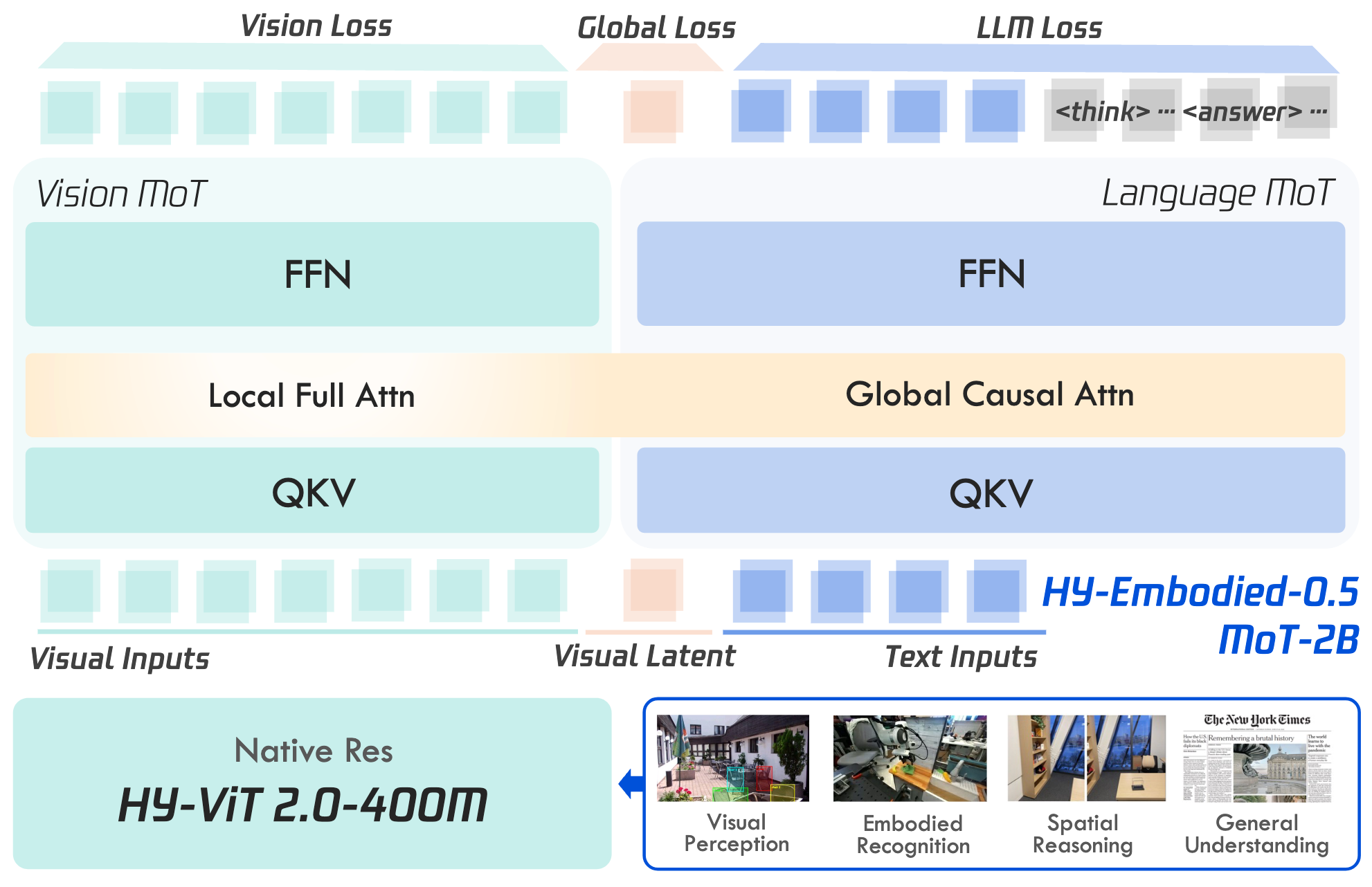
Xumin Yu*, Zuyan Liu*, Ziyi Wang*, He Zhang*, Yongming Rao#, Fangfu Liu, Yani Zhang, Ruowen Zhao, Oran Wang, Yves Liang, Haitao Lin, Minghui Wang, Yubo Dong, Kevin Cheng, Bolin Ni, Rui Huang, Han Hu, Zhengyou Zhang, Linus, Shunyu Yao [arXiv] [Code] [Models] HY-Embodied-0.5 is the first version of our embodied foundation models for real-world agents, attaining best performance on 16 out of 22 widely used benchmarks of visual perception, spatial intelligence and embodied reasoning. |
|
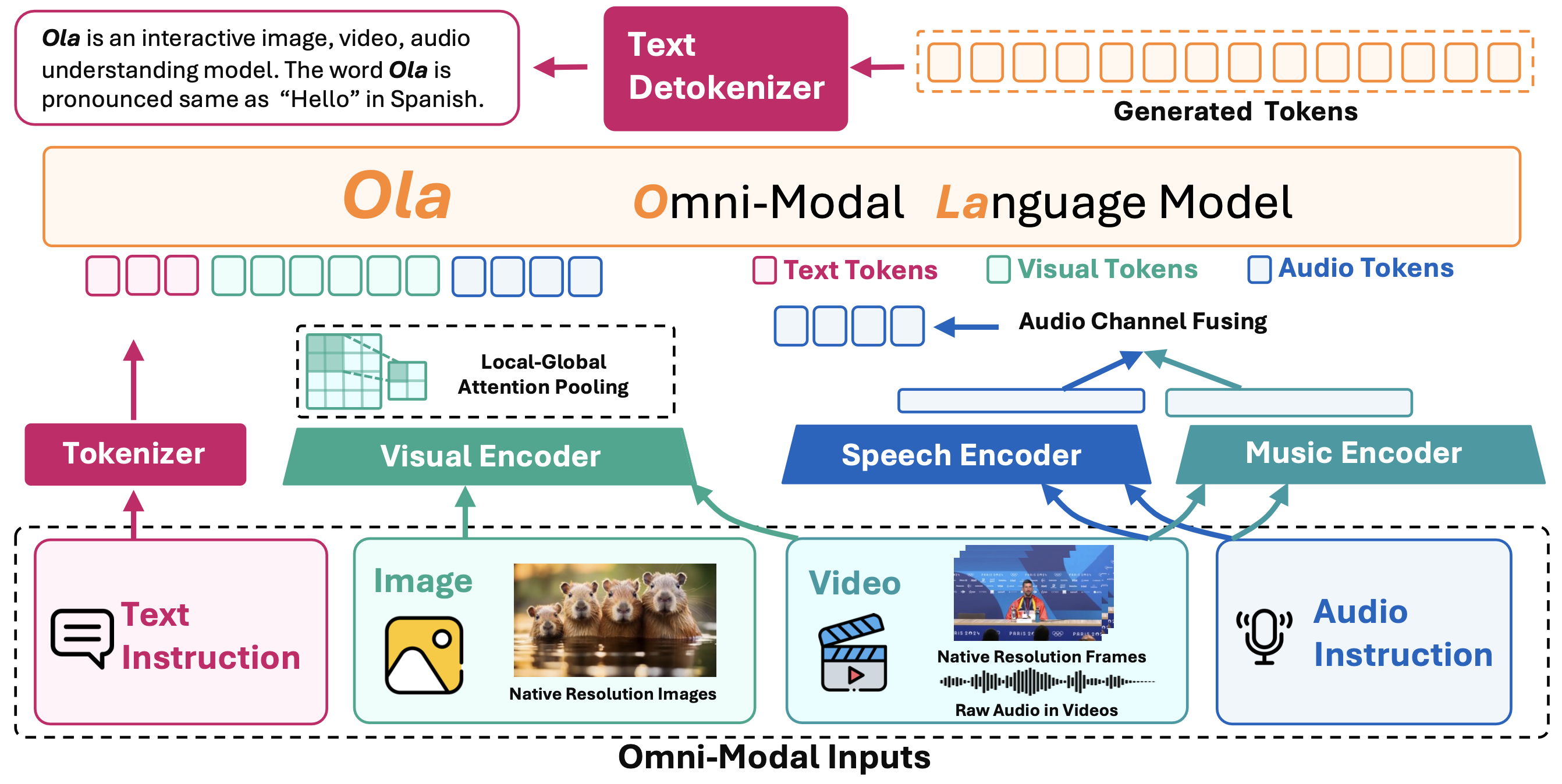
Zuyan Liu*, Yuhao Dong*, Jiahui Wang, Ziwei Liu, Han Hu, Jiwen Lu#, Yongming Rao#, [arXiv] [Code] [Project Page] Ola is our exploration for omni-model language models supporting vision, audio and text inputs. We develop a progressive alignment method to effectively learn multimodal knowledge and help the model to surpass existing open omni-modal LLMs of similar sizes across all modalities. |
|
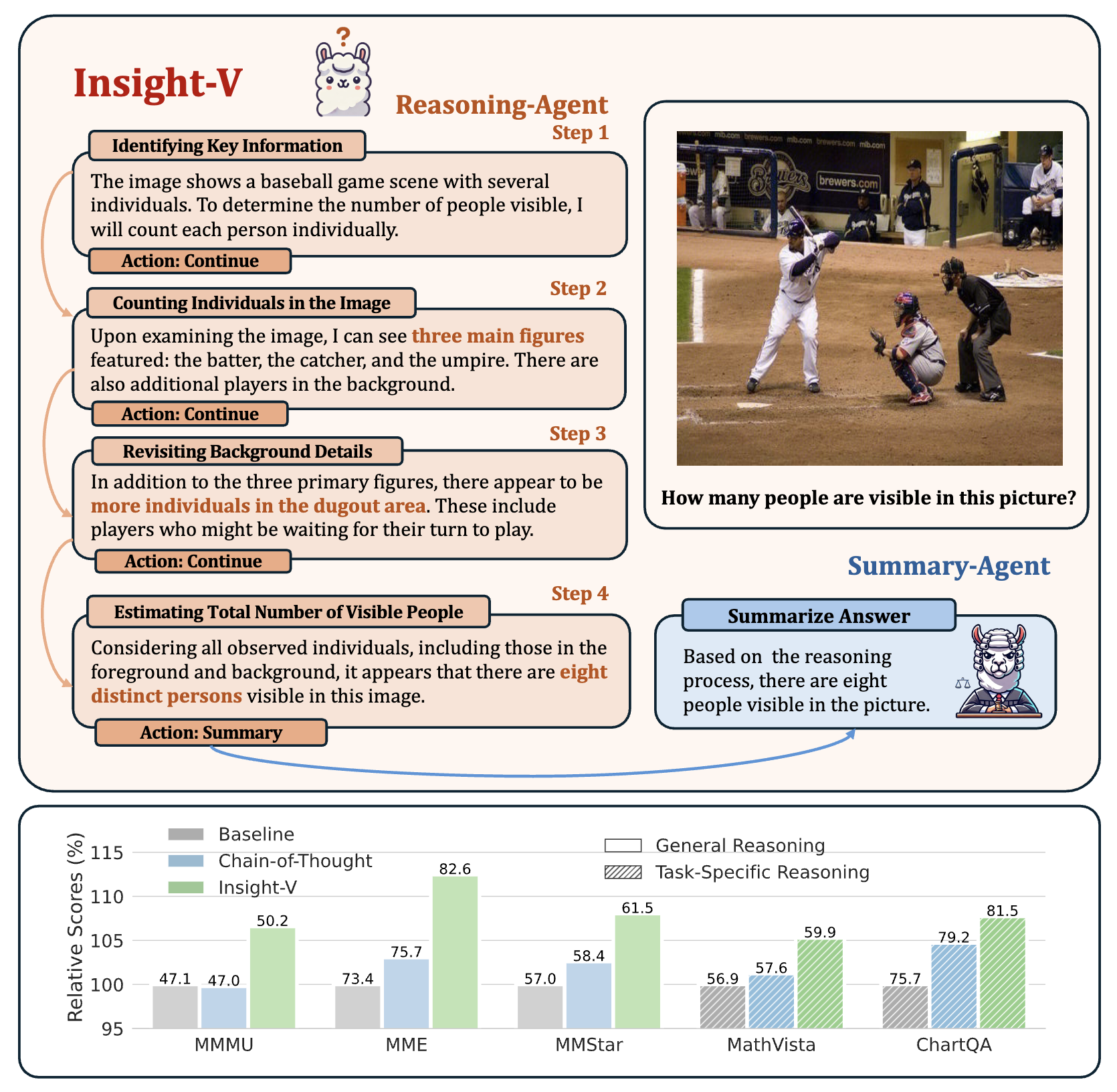
Yuhao Dong*, Zuyan Liu*, Hai-Long Sun, Jingkang Yang, Han Hu, Yongming Rao#, Ziwei Liu# IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 Highlight [arXiv] [Code] Insight-V is a early solution for long-chain reasoning of multimodal large language models. We developed a method to create multimodal long CoT data from basic instruct models, showing performance gains from deeper reasoning. |

|
Zuyan Liu*, Yuhao Dong*, Ziwei Liu, Han Hu, Jiwen Lu#, Yongming Rao# International Conference on Learning Representations (ICLR), 2025 [arXiv] [Code] [Project Page] Oryx is a unified multimodal architecture for the spatial-temporal understanding of images, videos, and multi-view 3D scenes, offering an on-demand solution to seamlessly and efficiently process visual inputs with arbitrary spatial sizes and temporal lengths. |
|
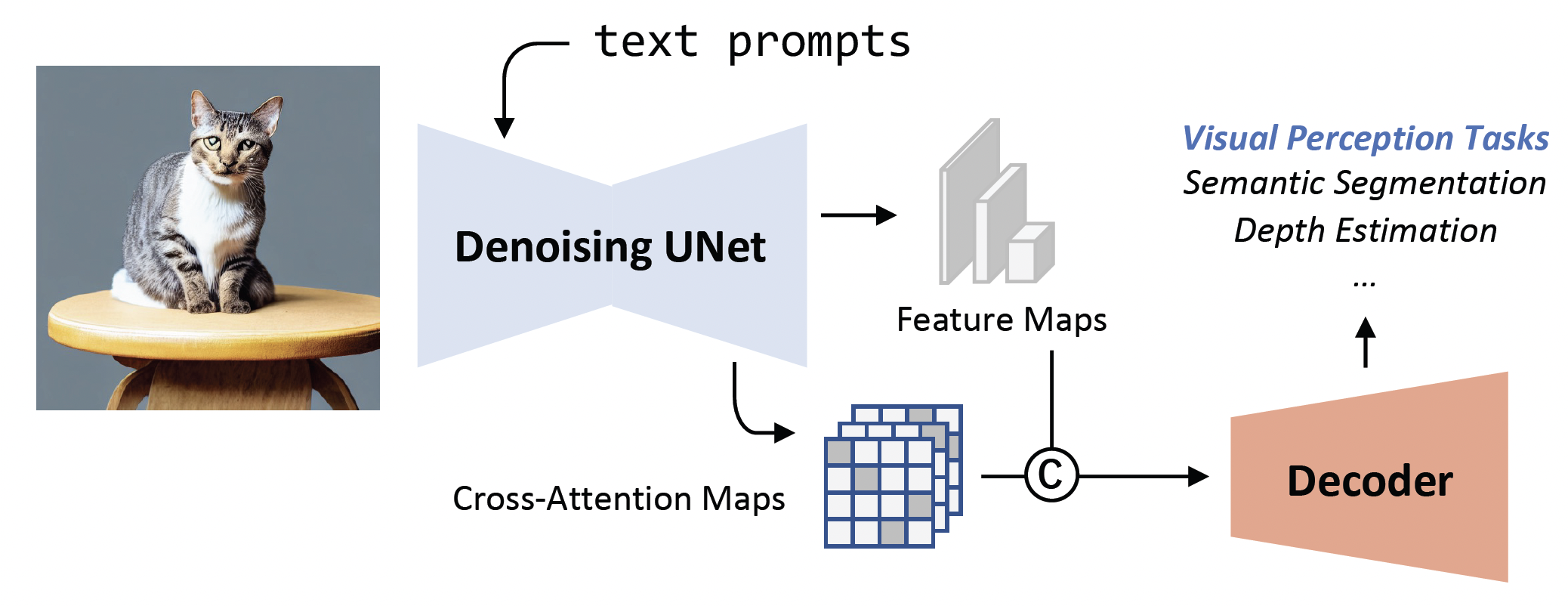
Wenliang Zhao*, Yongming Rao*, Zuyan Liu*, Benlin Liu Jie Zhou, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2023 [arXiv] [Code] [Project Page] [Rank 1st on NYUv2 Depth Estimation] VPD (Visual Perception with Pre-trained Diffusion Models) is a framework that leverages the high-level and low-level knowledge of a pre-trained text-to-image diffusion model to downstream visual perception tasks. |
|
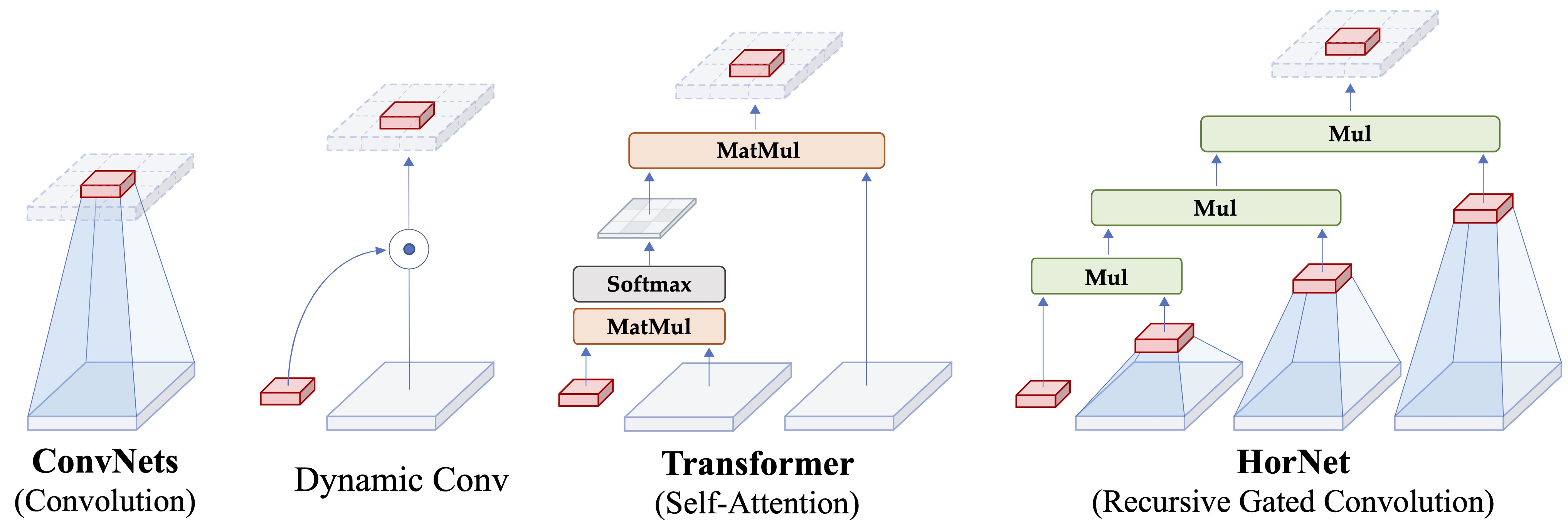
Yongming Rao*, Wenliang Zhao*, Yansong Tang, Jie Zhou , Ser-Nam Lim , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2022 [arXiv] [Code] [Project Page] [中文解读] HorNet is a family of generic vision backbones that perform explicit high-order spatial interactions based on Recursive Gated Convolution. |

|
Yongming Rao*, Wenliang Zhao*, Guangyi Chen, Yansong Tang, Zheng Zhu , Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] [Project Page] [中文解读] DenseCLIP is a new framework for dense prediction by implicitly and explicitly leveraging the pre-trained knowledge from CLIP. |
|
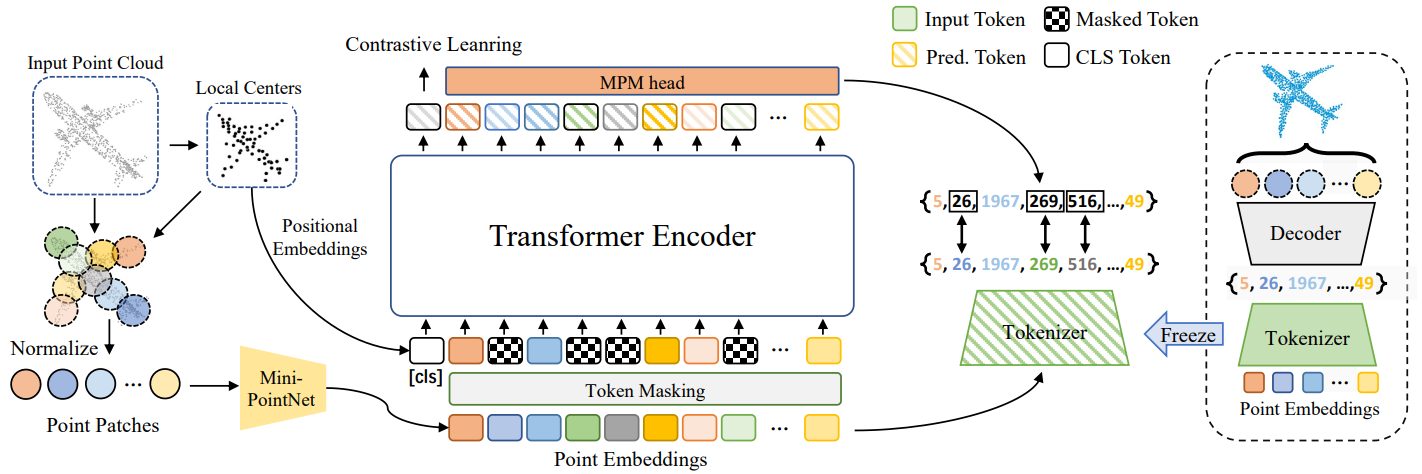
Xumin Yu*, Lulu Tang*, Yongming Rao*, Tiejun Huang, Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] [Project Page] [中文解读] Point-BERT is a new paradigm for learning Transformers in an unsupervised manner by generalizing the concept of BERT onto 3D point cloud data. |

|
Yongming Rao*, Wenliang Zhao*, Zheng Zhu , Jiwen Lu , Jie Zhou Conference on Neural Information Processing Systems (NeurIPS), 2021 [arXiv] [Code] [Project Page] [中文解读] Global Filter Networks is a transformer-style architecture that learns long-term spatial dependencies in the frequency domain with log-linear complexity. |

|
Yongming Rao, Wenliang Zhao, Benlin Liu , Jiwen Lu , Jie Zhou , Cho-Jui Hsieh Conference on Neural Information Processing Systems (NeurIPS), 2021 [arXiv] [Code] [Project Page] [Video] [中文解读] We present a dynamic token sparsification framework to prune redundant tokens in vision transformers progressively and dynamically based on the input. |

|
Xumin Yu*, Yongming Rao*, Ziyi Wang, Zuyan Liu, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 Oral Presentation [arXiv] [Code] [中文解读] PoinTr is a transformer-based framework that reformulates point cloud completion as a set-to-set translation problem. |
|
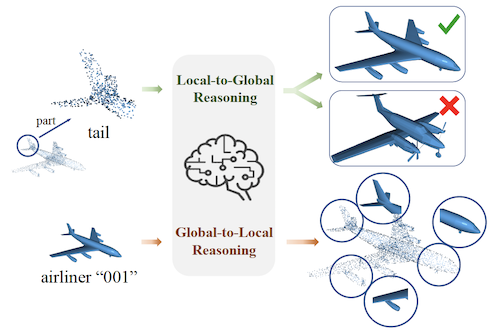
Yongming Rao, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020 IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2022 [arXiv] [Code] We present an unsupervised point cloud representation learning method based on global-local bidirectional reasoning, which largely advances the state-of-the-art of unsupervised point cloud understanding and outperforms recent supervised methods. |
|
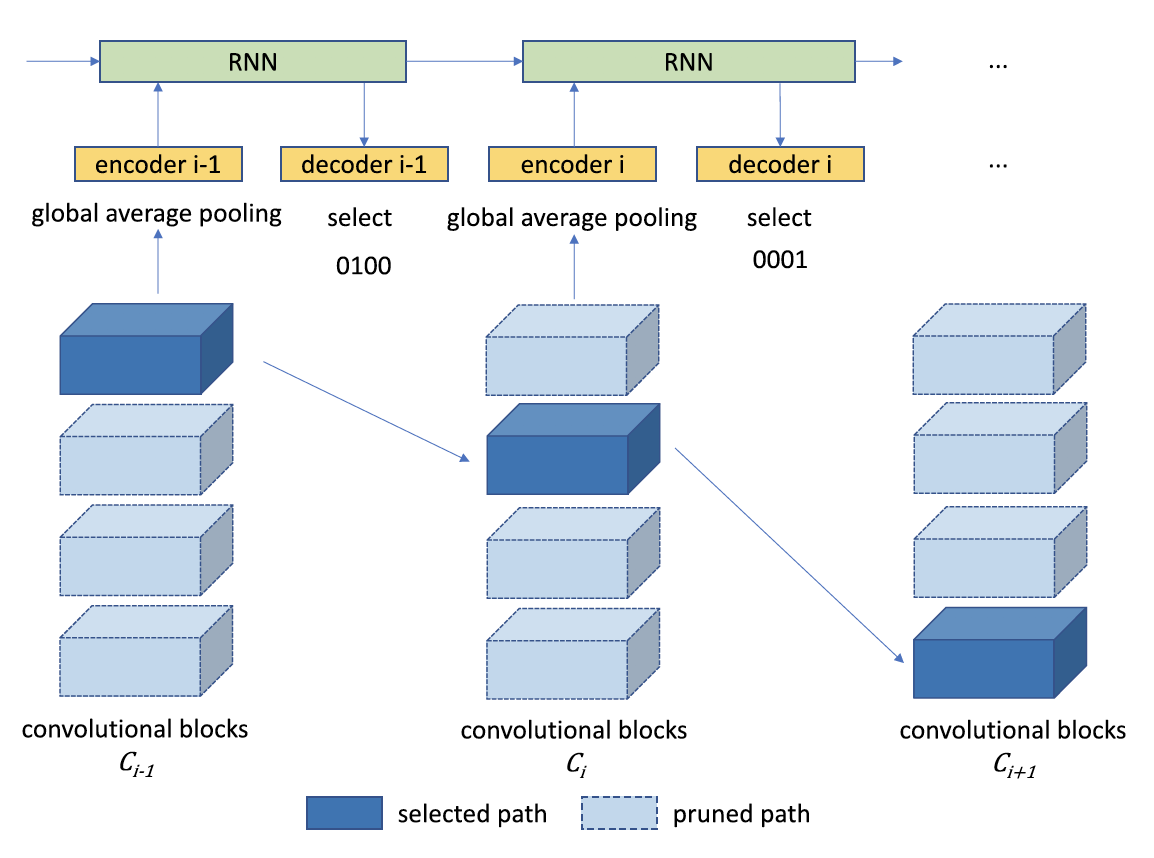
Yongming Rao, Jiwen Lu , Ji Lin , Jie Zhou IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2019 [PDF] [Code] [Conference Version (NeurIPS 2017)] We propose a generic Runtime Network Routing (RNR) framework for efficient image classification, which selects an optimal path inside the network. Our method can be applied to off-the-shelf neural network structures and easily extended to various application scenarios. |
Please refer to my Google Scholar for the full publication list.
|
|
|
|
|
|