|
I am currently a senior researcher at Tencent, working on large multimodal models and AI foundation models. I obtained my Ph.D degree from Tsinghua University in 2023, advised by Prof. Jiwen Lu . Before that, I received B.Eng. degree from the Department of Electronic Engineering, Tsinghua University in 2018. We are hiring interns. Please feel free to drop me an email if you are interested in working with us. Email / CV / Google Scholar / Github |

|
|
* indicates equal contribution |
|
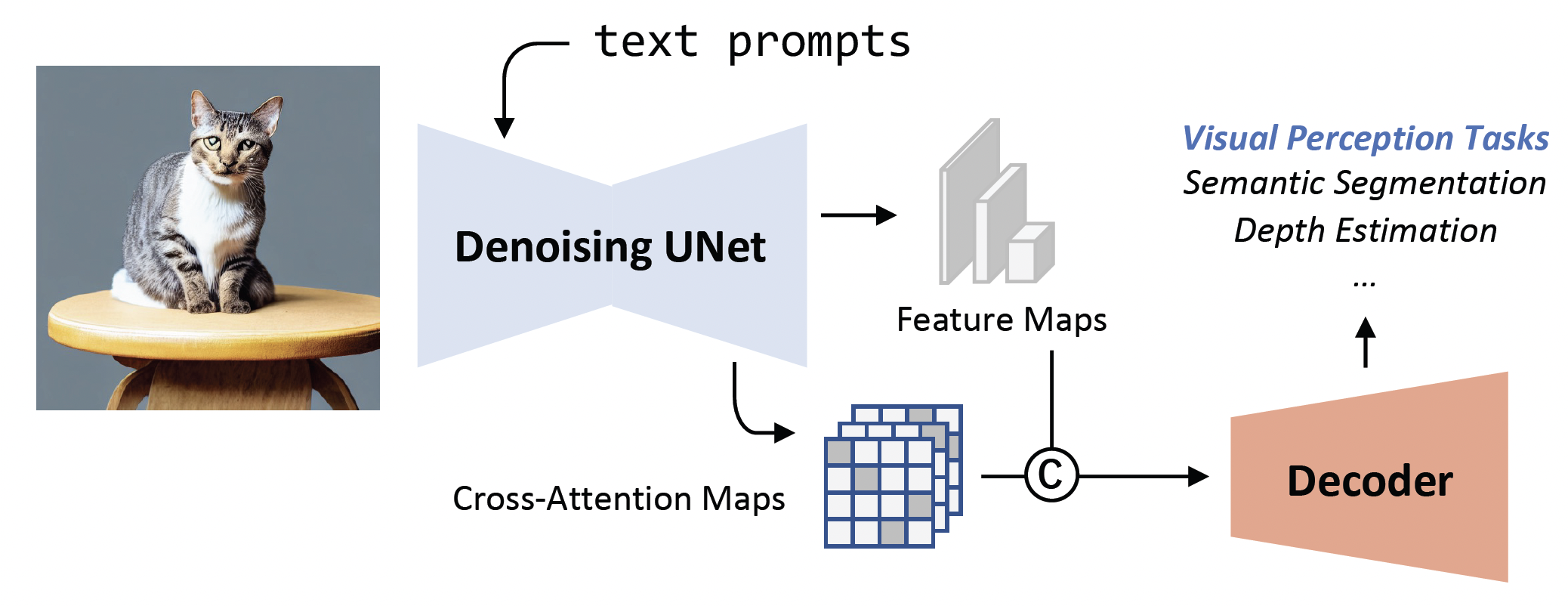
Wenliang Zhao*, Yongming Rao*, Zuyan Liu*, Benlin Liu Jie Zhou, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2023 [arXiv] [Code] [Project Page] [Rank 1st on NYUv2 Depth Estimation] VPD (Visual Perception with Pre-trained Diffusion Models) is a framework that leverages the high-level and low-level knowledge of a pre-trained text-to-image diffusion model to downstream visual perception tasks. |
|
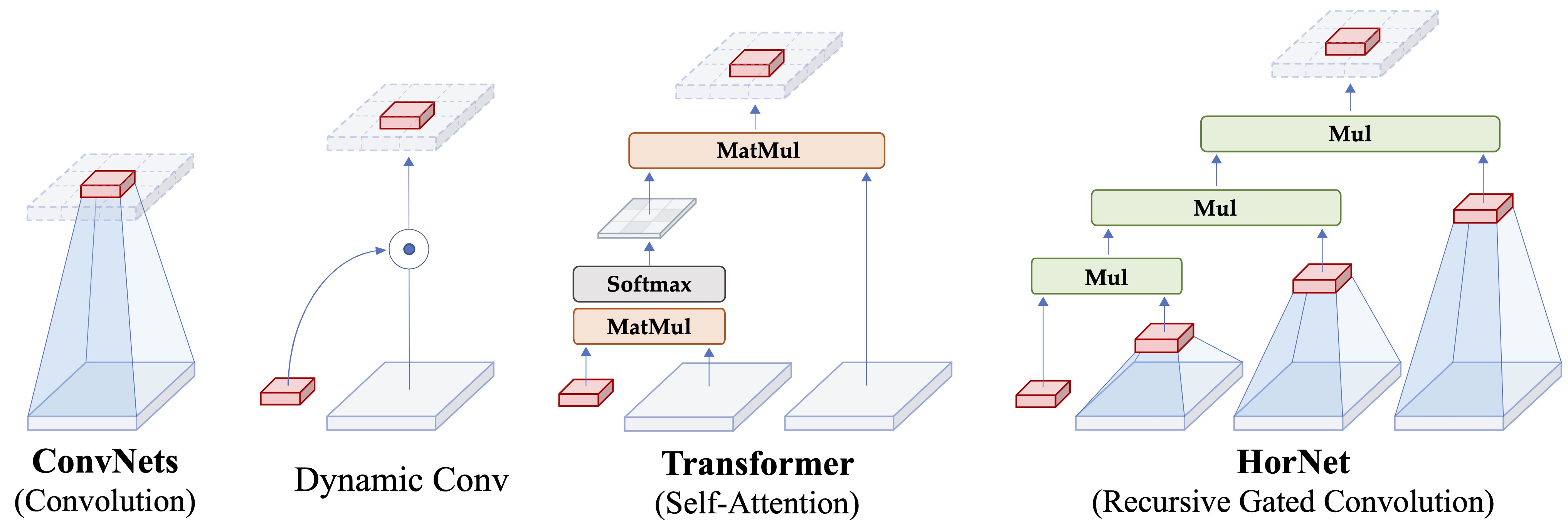
Yongming Rao*, Wenliang Zhao*, Yansong Tang, Jie Zhou , Ser-Nam Lim , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2022 [arXiv] [Code] [Project Page] [中文解读] HorNet is a family of generic vision backbones that perform explicit high-order spatial interactions based on Recursive Gated Convolution. |
|
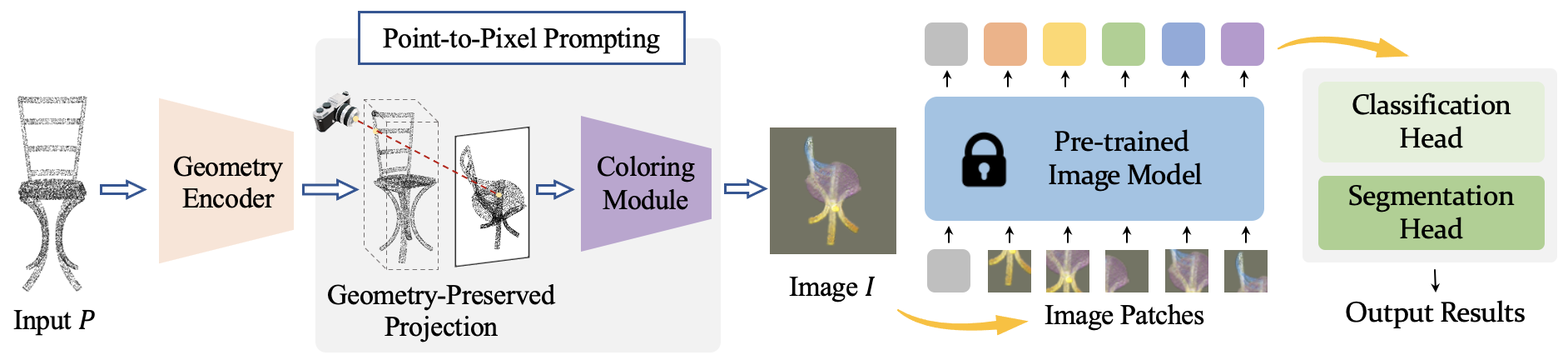
Ziyi Wang*, Xumin Yu*, Yongming Rao*, Jie Zhou , Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2022 [arXiv] [Code] [Project Page] [中文解读] P2P is a framework to leverage large-scale pre-trained image models for 3D point cloud analysis. |

|
Yongming Rao*, Wenliang Zhao*, Guangyi Chen, Yansong Tang, Zheng Zhu , Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] [Project Page] [中文解读] DenseCLIP is a new framework for dense prediction by implicitly and explicitly leveraging the pre-trained knowledge from CLIP. |
|
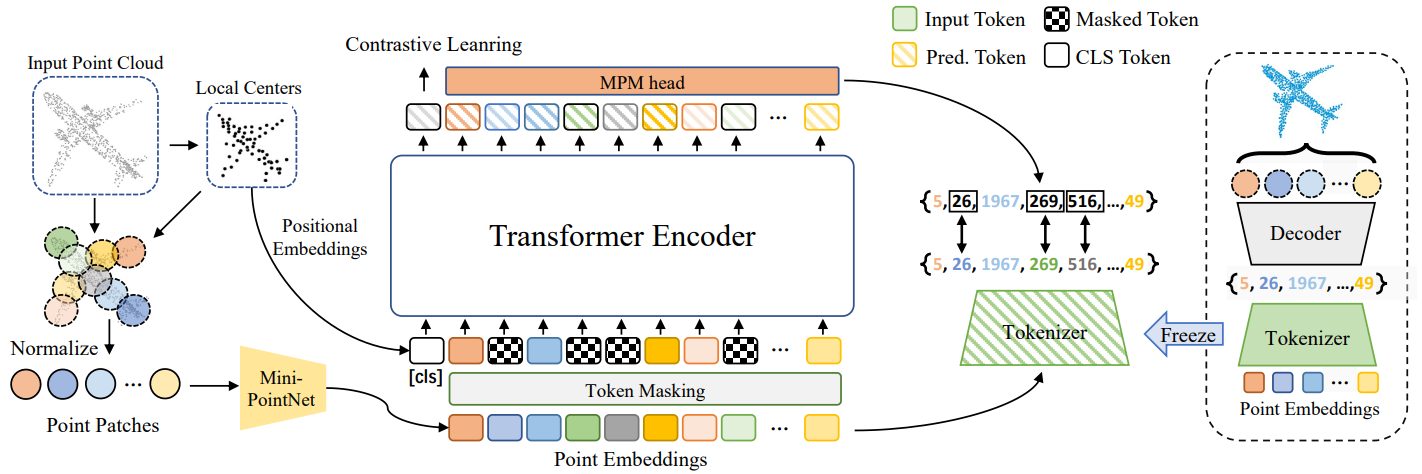
Xumin Yu*, Lulu Tang*, Yongming Rao*, Tiejun Huang, Jie Zhou , Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [arXiv] [Code] [Project Page] [中文解读] Point-BERT is a new paradigm for learning Transformers in an unsupervised manner by generalizing the concept of BERT onto 3D point cloud data. |

|
Yongming Rao*, Wenliang Zhao*, Zheng Zhu , Jiwen Lu , Jie Zhou Conference on Neural Information Processing Systems (NeurIPS), 2021 [arXiv] [Code] [Project Page] [中文解读] Global Filter Networks is a transformer-style architecture that learns long-term spatial dependencies in the frequency domain with log-linear complexity. |

|
Yongming Rao, Wenliang Zhao, Benlin Liu , Jiwen Lu , Jie Zhou , Cho-Jui Hsieh Conference on Neural Information Processing Systems (NeurIPS), 2021 [arXiv] [Code] [Project Page] [Video] [中文解读] We present a dynamic token sparsification framework to prune redundant tokens in vision transformers progressively and dynamically based on the input. |

|
Xumin Yu*, Yongming Rao*, Ziyi Wang, Zuyan Liu, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 Oral Presentation [arXiv] [Code] [中文解读] PoinTr is a transformer-based framework that reformulates point cloud completion as a set-to-set translation problem. |
|
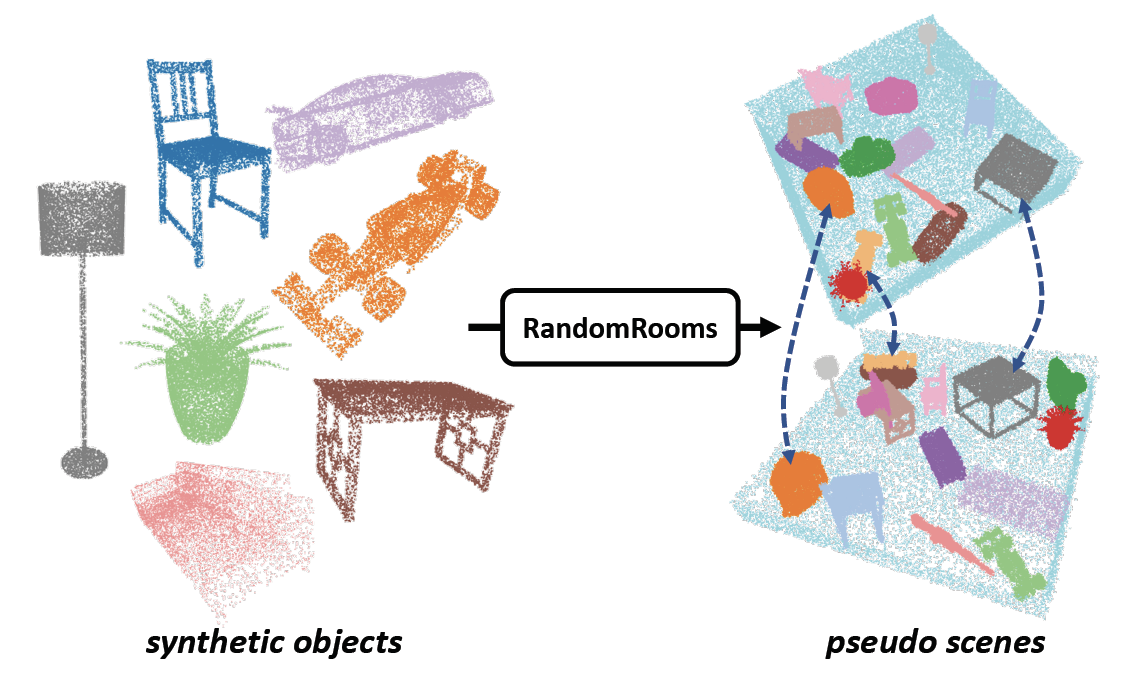
Yongming Rao*, Benlin Liu*, Yi Wei , Jiwen Lu , Cho-Jui Hsieh , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [arXiv] We propose to generate random layouts of a scene by making use of the objects in the synthetic CAD dataset and learn the 3D scene representation by applying object-level contrastive learning on two random scenes generated from the same set of synthetic objects. |
|
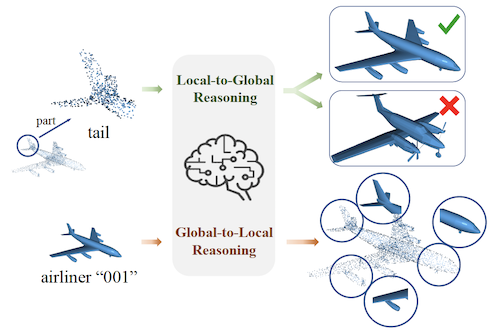
Yongming Rao, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020 IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2022 [arXiv] [Code] We present an unsupervised point cloud representation learning method based on global-local bidirectional reasoning, which largely advances the state-of-the-art of unsupervised point cloud understanding and outperforms recent supervised methods. |
|
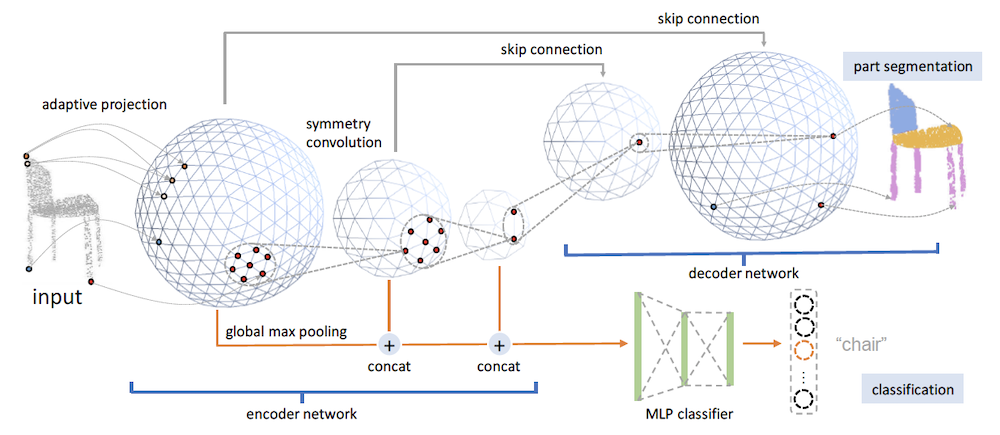
Yongming Rao, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019 [PDF] [Supplement] We designed Spherical Fractal Convolution Neural Networks (SFCNN) for rotation-invariant point cloud feature learning. |
|
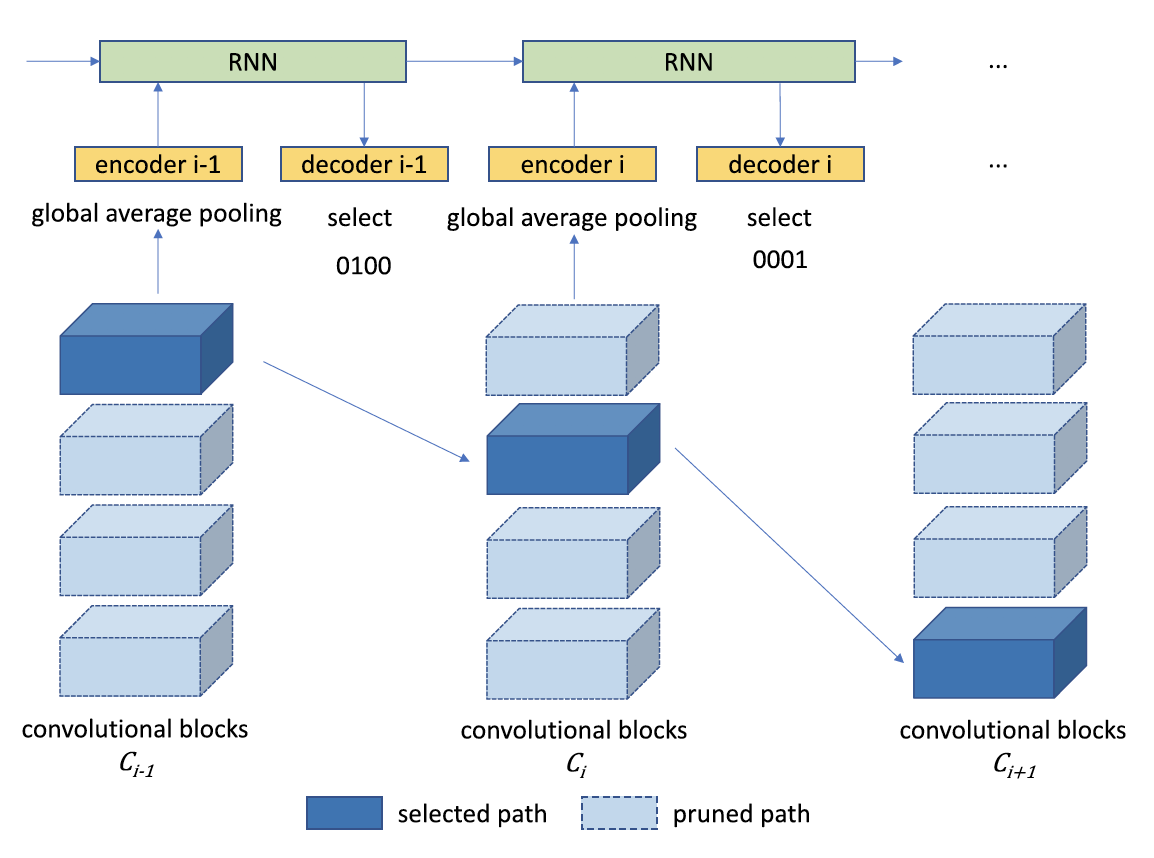
Yongming Rao, Jiwen Lu , Ji Lin , Jie Zhou IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2019 [PDF] [Code] [Conference Version (NeurIPS 2017)] We propose a generic Runtime Network Routing (RNR) framework for efficient image classification, which selects an optimal path inside the network. Our method can be applied to off-the-shelf neural network structures and easily extended to various application scenarios. |

|
Yi Wei , Shaohui Liu, Yongming Rao, Wang Zhao, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 Oral Presentation [arXiv] [Code] [Project page] [Video] We present a new multi-view depth estimation method that utilizes both conventional SfM reconstruction and learning-based priors over the recently proposed neural radiance fields (NeRF). |
|
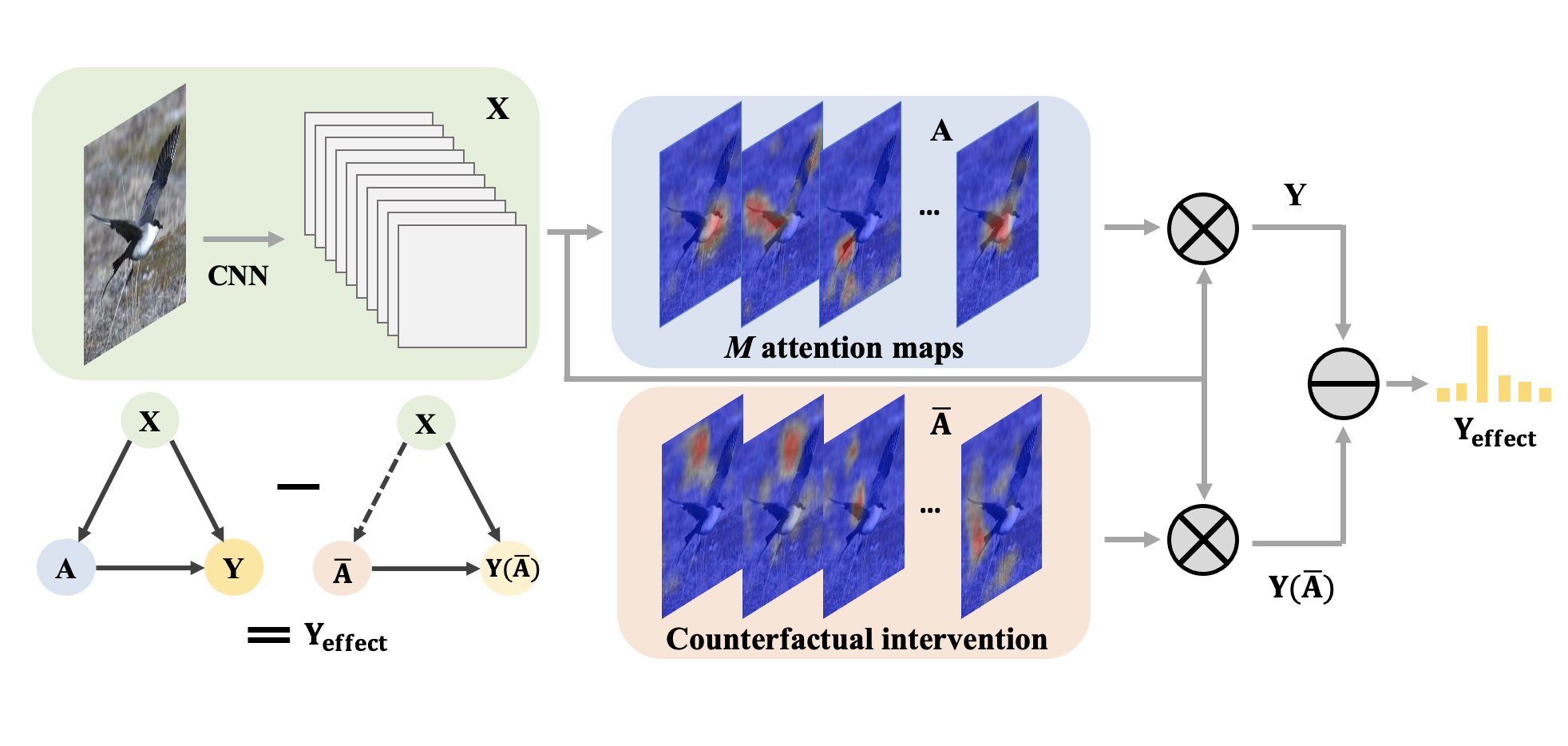
Yongming Rao*, Guangyi Chen*, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [arXiv] [Code] We propose to learn the attention with counterfactual causality, which provides a tool to measure the attention quality and a powerful supervisory signal to guide the learning process. |
|
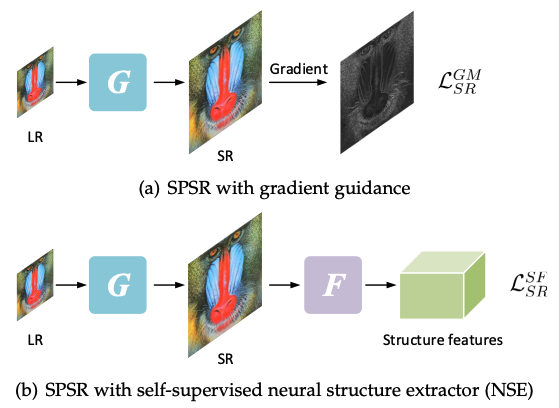
Cheng Ma , Yongming Rao, Jiwen Lu , Jie Zhou IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2021 [arXiv] [Code] We propose to learn a neural structure extractor unsupervisedly to extract structural patterns in images and use it to supervise SR models. |

|
Wenliang Zhao*, Yongming Rao*, Ziyi Wang, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [arXiv] [Code] We present a deep interpretable metric learning (DIML) that adopts a structural matching strategy to explicitly aligns the spatial embeddings by computing an optimal matching flow between feature maps of the two images. |
|
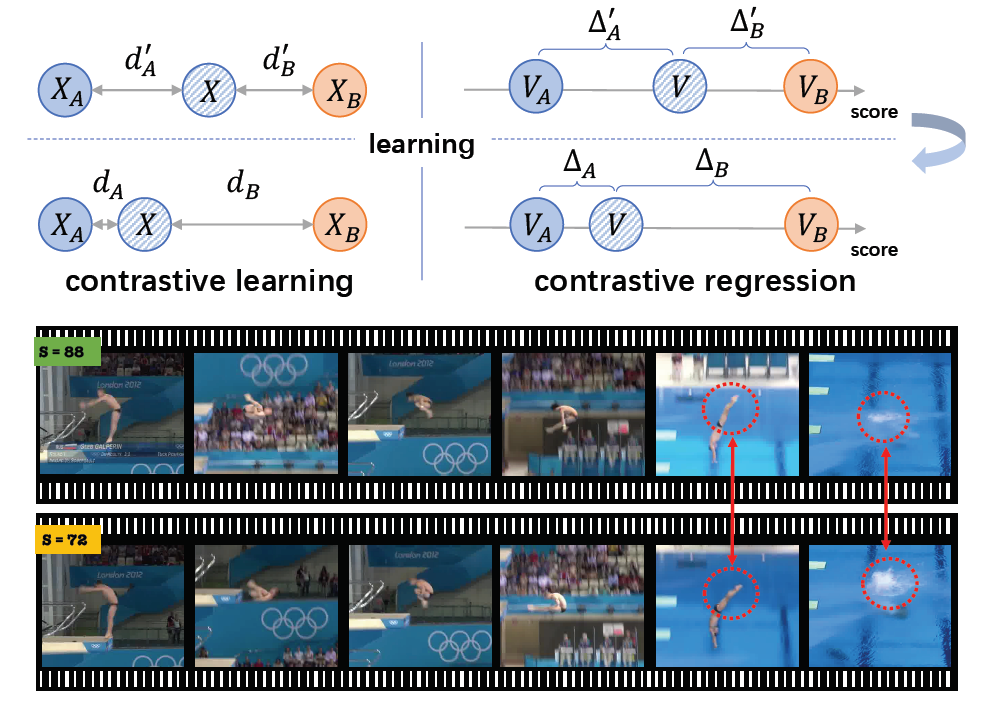
Xumin Yu*, Yongming Rao*, Wenliang Zhao, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2021 [arXiv] [Code] We propose a new contrastive regression (CoRe) framework to learn the relative scores by pair-wise comparison, which highlights the differences between videos and guides the models to learn the key hints for action quality assessment. |
|
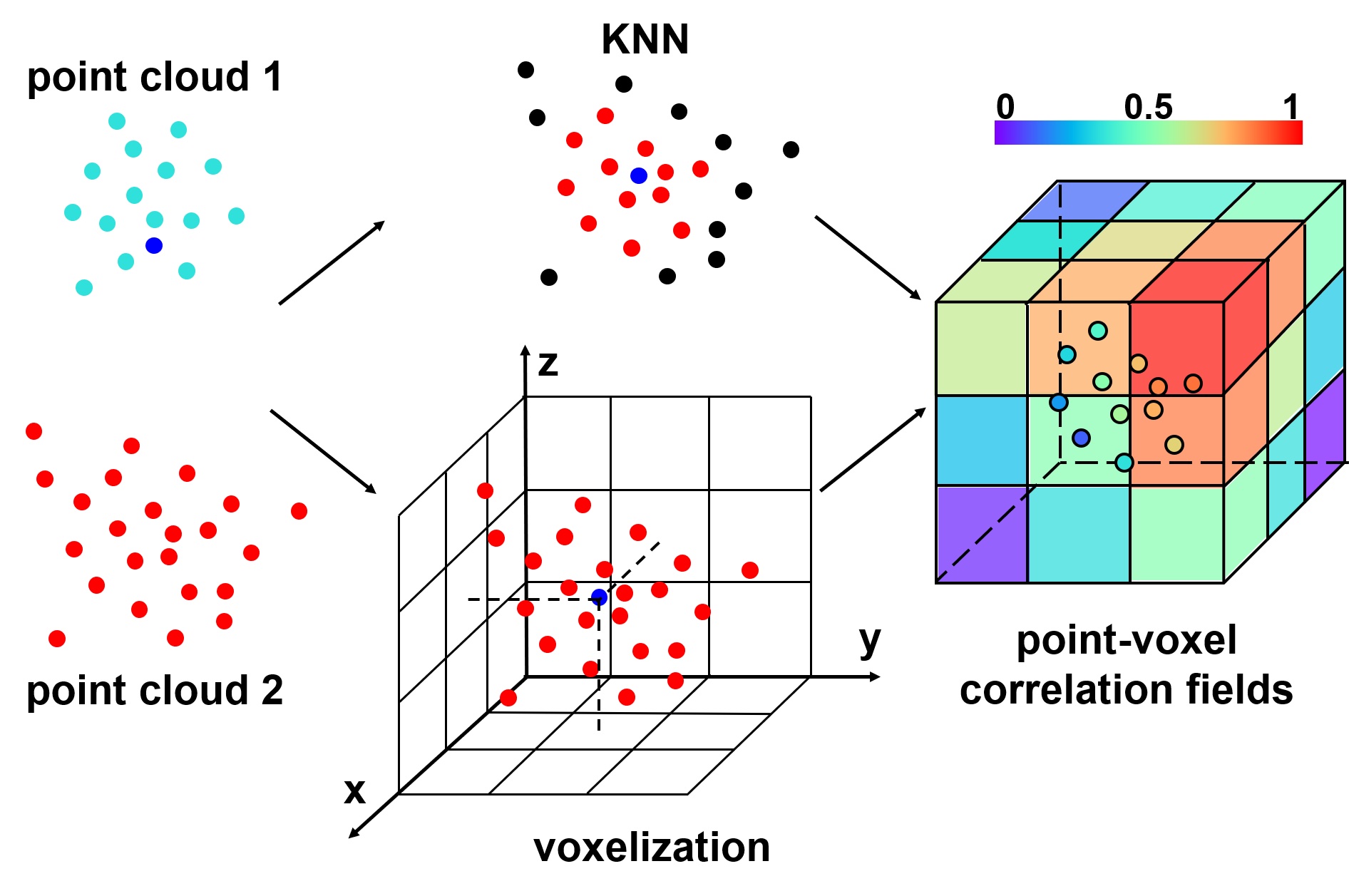
Yi Wei *, Ziyi Wang*, Yongming Rao*, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [arXiv] [Code] We present point-voxel correlation fields for 3D scene flow estimation which migrates the high performance of RAFT and provides a solution to build structured all-pairs correlation fields for unstructured point clouds. |
|
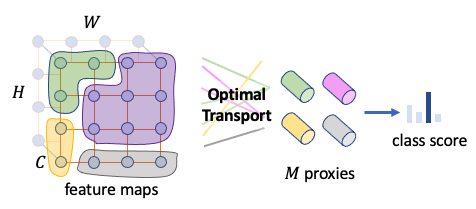
Benlin Liu *, Yongming Rao*, Jiwen Lu , Jie Zhou , Cho-Jui Hsieh AAAI Conference on Artificial Intelligence (AAAI), 2021 [PDF] We present a new Multi-Proxy Wasserstein Classifier to imporve the image classification models by calculating a non-uniform matching flow between the elements in the feature map of a sample and multiple proxies of a class using optimal transport theory. |
|
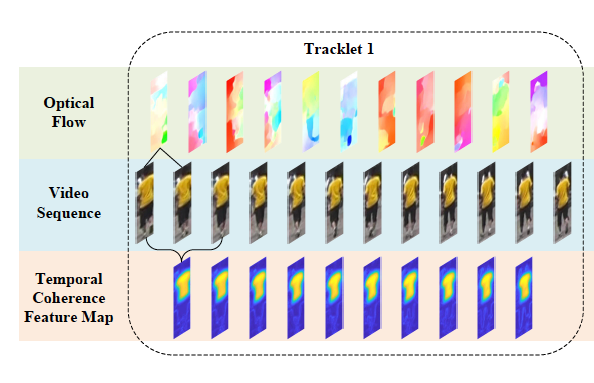
Guangyi Chen *, Yongming Rao*, Jiwen Lu , Jie Zhou European Conference on Computer Vision (ECCV), 2020 [PDF] We show temporal coherence plays a more critical role than temporal motion for video-based person re-identification and develop a Adversarial Feature Augmentation (AFA) to highlight temporal coherence. |
|
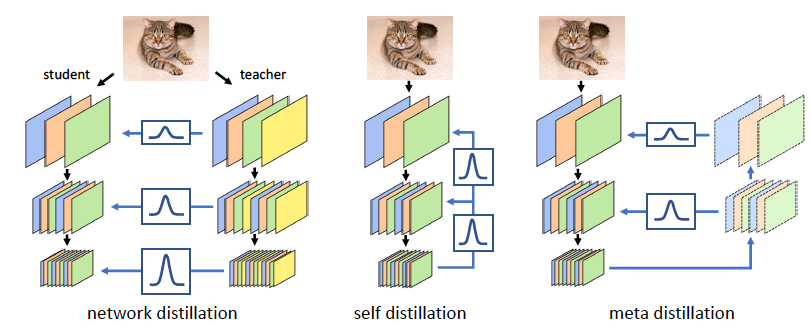
Benlin Liu , Yongming Rao, Jiwen Lu , Jie Zhou , Cho-Jui Hsieh European Conference on Computer Vision (ECCV), 2020 [arXiv] We boost the performance of CNNs by learning soft targets for shallow layers via meta-learning. |
|
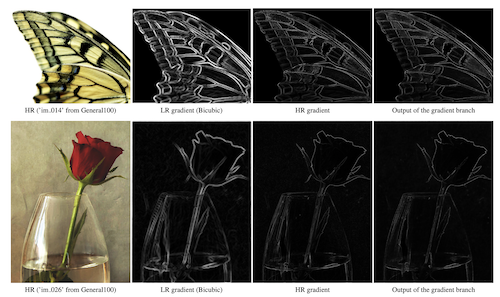
Cheng Ma , Yongming Rao, Yean Cheng, Ce Chen, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020 [arXiv] [Code] We propose to leverage gradient information as an extra supervision signal to restore structures while generating natural SR images. |
|
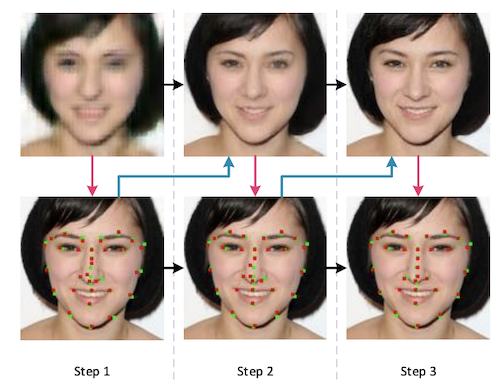
Cheng Ma , Zhenyu Jiang , Yongming Rao, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020 [arXiv] [Code] We propose a deep face super-resolution method with iterative collaboration between two recurrent networks which focus on facial image recovery and landmark estimation respectively |
|
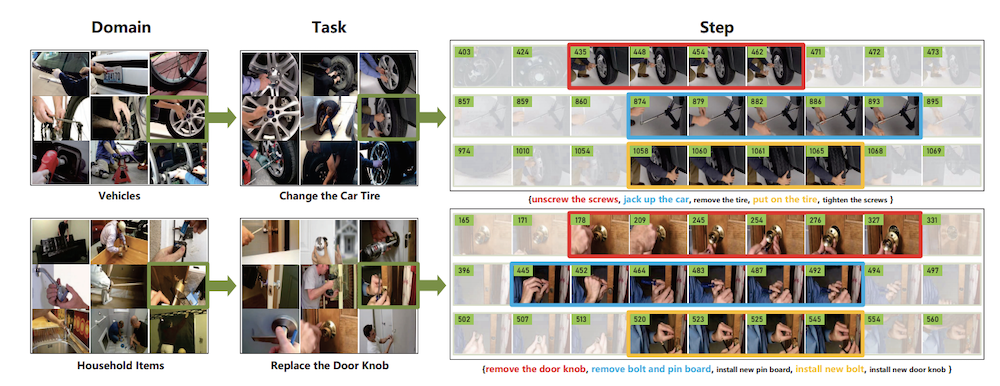
Yansong Tang , Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019 [arXiv] [Project Page] [Annotation Tool] COIN is the largest and most comprehensive instructional video analysis dataset with rich annotations. |
|
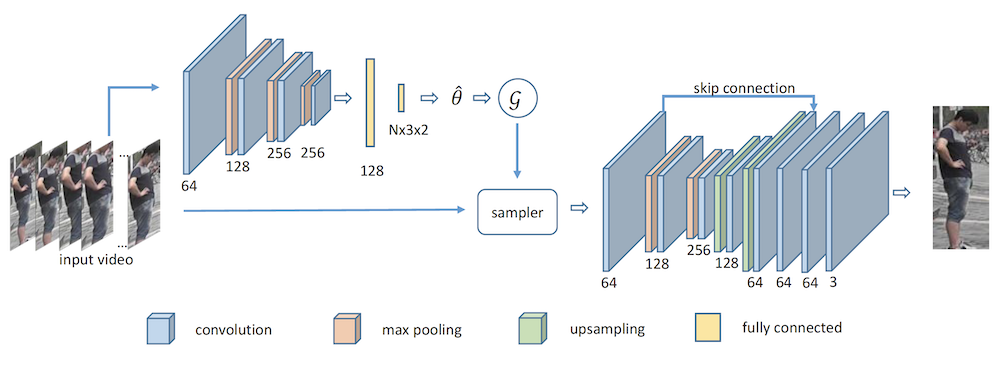
Yongming Rao, Jiwen Lu , Jie Zhou International Journal of Computer Vision (IJCV, IF: 6.07), 2019 [PDF] [Code] We propose a discriminative aggregation network (DAN) method for video-based face recognition and person re-identification, which aims to integrate information from video frames for feature representation effectively and efficiently. |
|
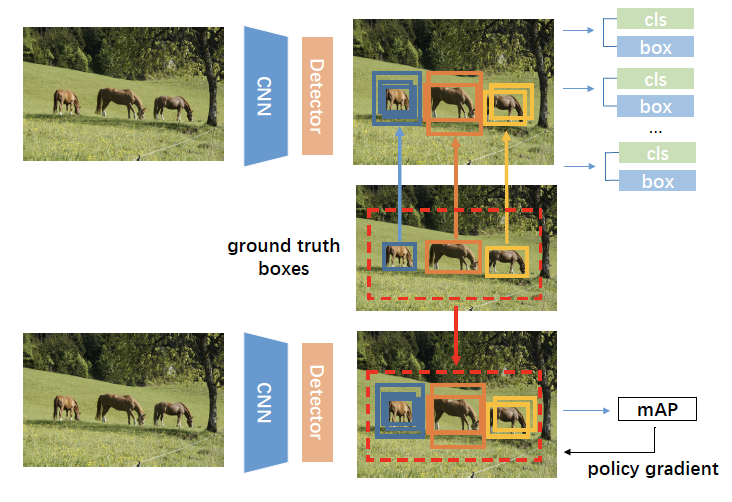
Yongming Rao, Dahua Lin , Jiwen Lu , Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018 Spotlight Presentation [PDF] [Supplement] We propose a simple yet effective method to learn globally optimized detector for object detection by directly optimizing mAP using the REINFORCE algorithm. |
|
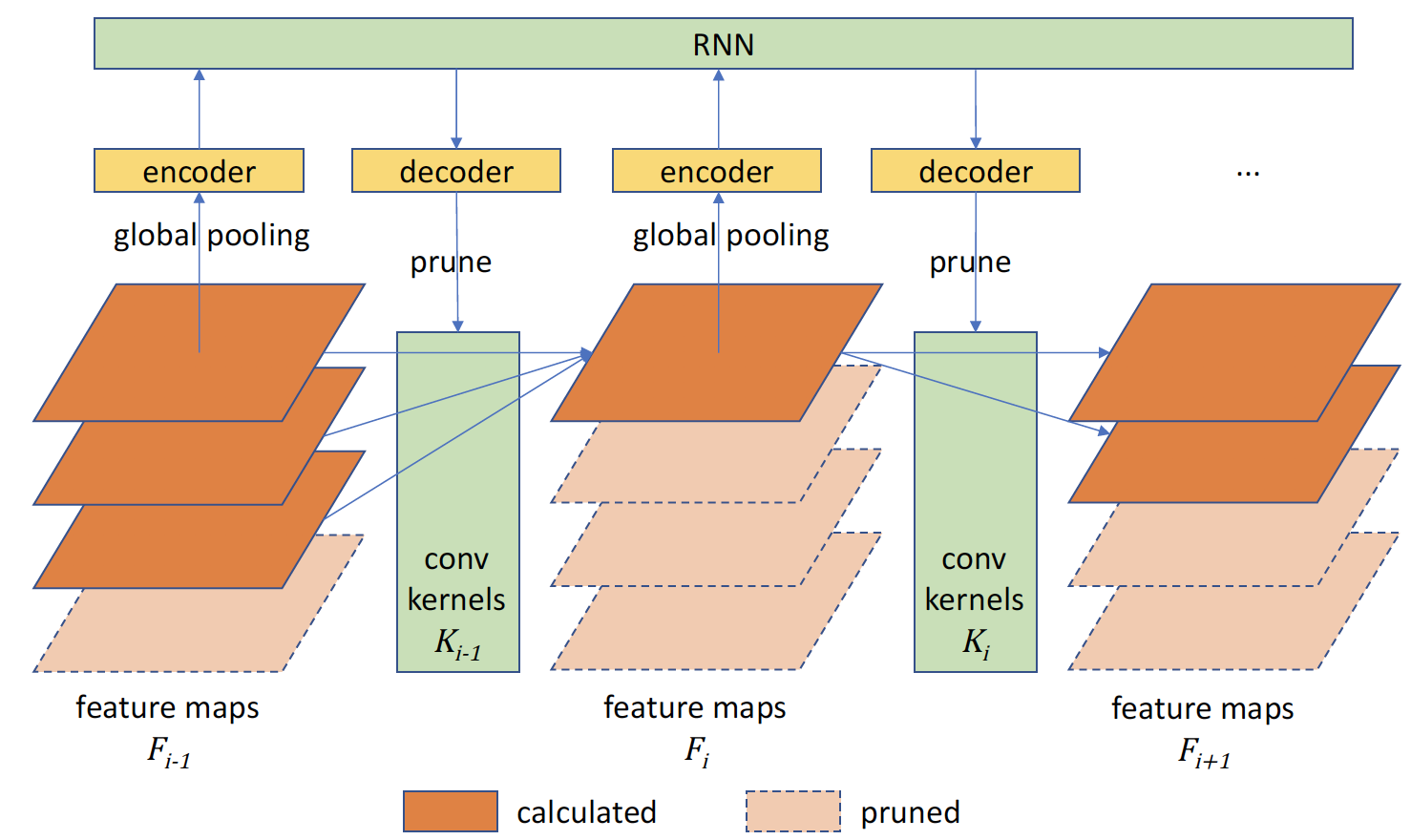
Ji Lin *, Yongming Rao*, Jiwen Lu , Jie Zhou Conference on Neural Information Processing Systems (NeurIPS), 2017 [PDF] [Code] We propose a Runtime Neural Pruning (RNP) framework which prunes the deep neural network dynamically at the runtime. |
|
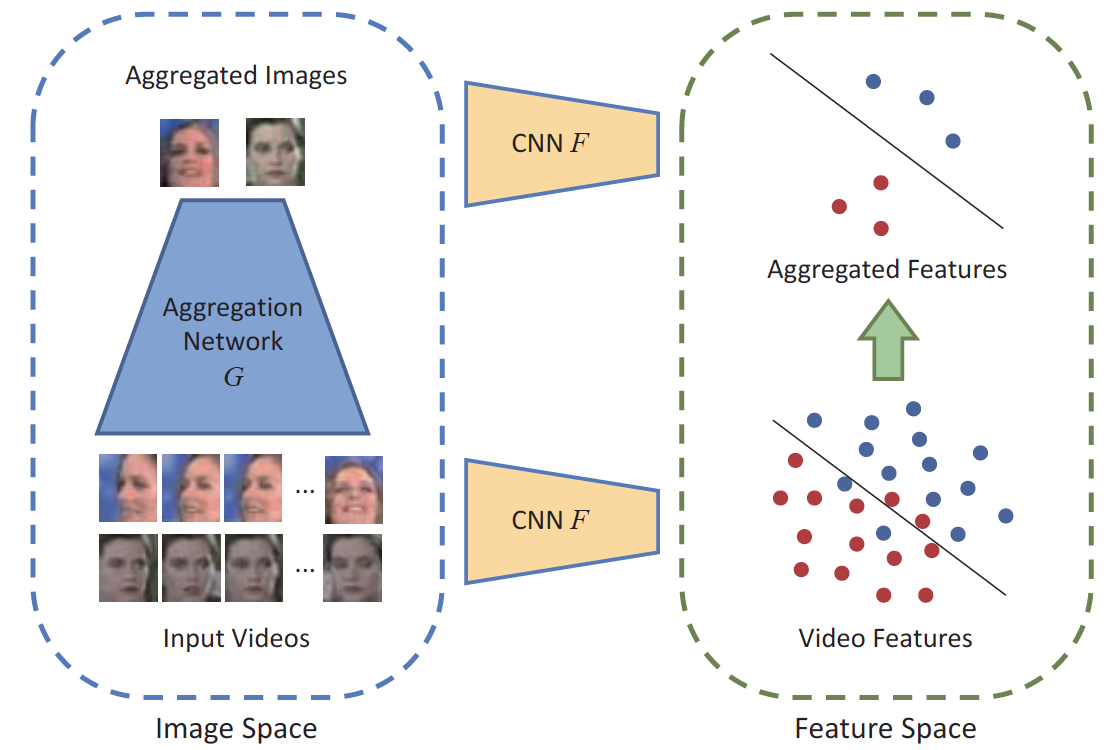
Yongming Rao, Ji Lin , Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2017 Spotlight Presentation [PDF] [Code] [Supplement] We propose a discriminative aggregation network (DAN) method for video face recognition, which aims to integrate information from video frames effectively and efficiently. |
|
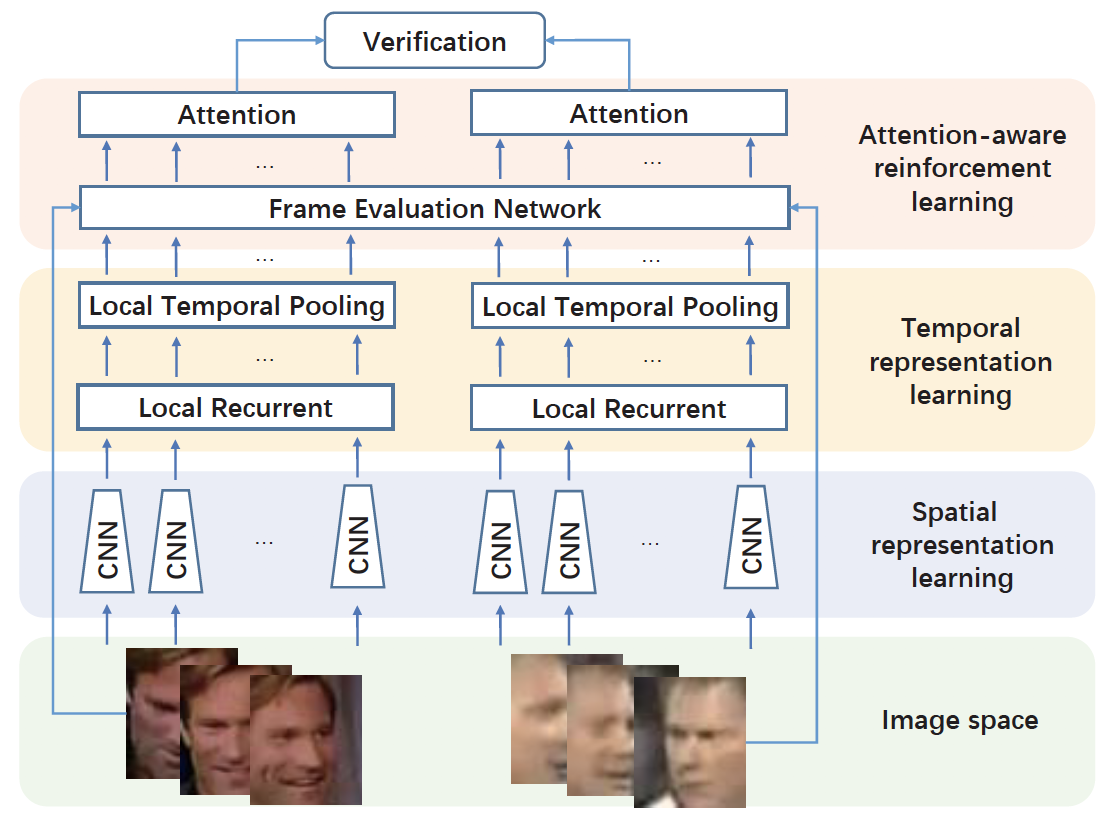
Yongming Rao, Jiwen Lu , Jie Zhou IEEE International Conference on Computer Vision (ICCV), 2017 [PDF] We propose an attention-aware deep reinforcement learning (ADRL) method for video face recognition, which aims to discard the misleading and confounding frames and find the focuses of attentions in face videos for person recognition. |
|
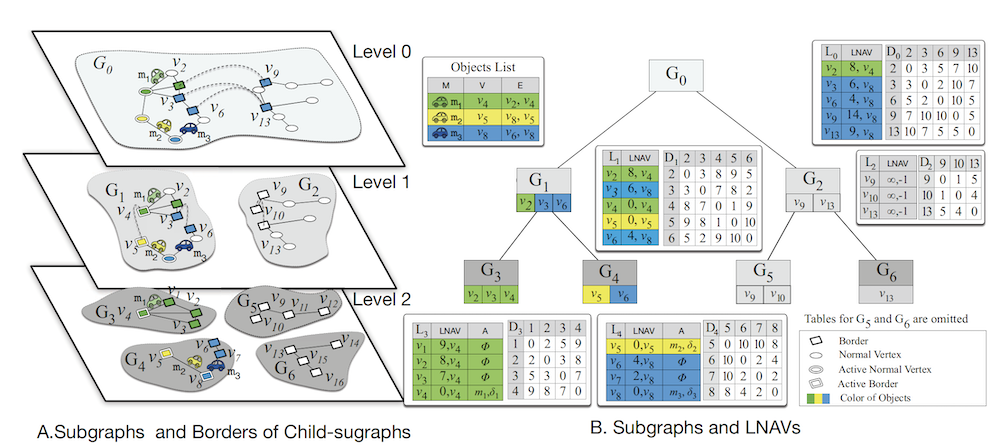
Bilong Shen, Ying Zhao, Guoliang Li, Weimin Zheng, Yue Qin, Bo Yuan, Yongming Rao IEEE International Conference on Data Engineering (ICDE), 2017 [PDF] We propose a new tree structure for moving objects kNN search with road-network constraints, which can be used in many real-world applications like taxi search. |
|
|
|
|
|
|
© Yongming Rao | Last updated: May 26, 2024